
Overview
You have a custom install on Red Hat Enterprise Linux (RHEL) and have encountered an issue where both ScaleArc instances in a HA pair are showing as Secondary. Further, the HA cluster settings cannot be modified and ScaleArc is giving an error stating that it was unable to update the setting on the Secondary server even though the action was done on what should be the primary node in the HA pair.
The UI is not loading or hanging after restarting ScaleArc.
Environment
- ScaleArc HA configuration
- Custom install on Red Hat Enterprise Linux (RHEL)
Solution
Checking the HA Settings will show both servers in a HA pair as secondary servers when there are internal inconsistencies in the cluster configuration database resulting in the inability to modify the ScaleArc cluster configuration.
Follow these steps to resolve this problem:
- Navigate to SETTINGS > HA Settings and click on the 'Restart' button to restart HA services, and confirm if the HA service restarts successfully and correctly pick up the Primary and Secondary instances in the HA pair.
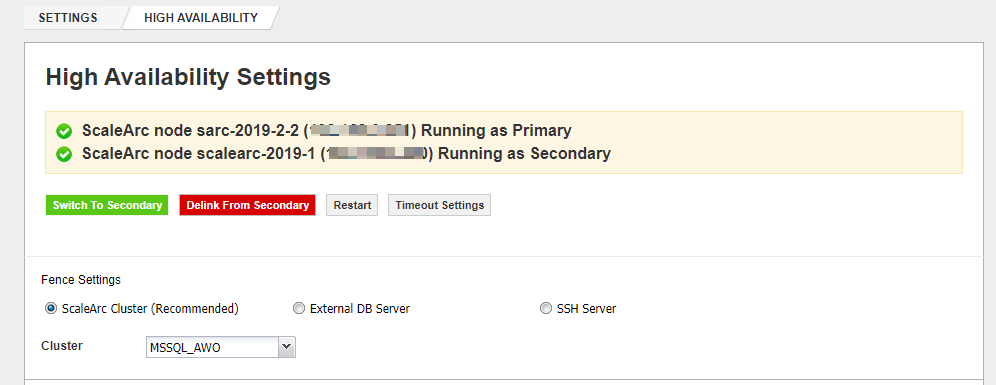
- If both instances still show as Secondary, connect to the one that was Primary before the issue occurred and click on 'Force to be Primary' button; the instance should then become Primary. Note that when an instance changes HA status this way, you will be automatically logged out and will be redirected to the login page in order to log in again.
- If the previous steps do not resolve the HA status inconsistency, check if there have been RHEL package updates that may have upgraded any of the RHEL packages from the default versions installed by ScaleArc to newer versions from the RHEL repository. ScaleArc has tight dependencies with specific versions of various packages and any inadvertent updates to the dependencies may result in incorrect functioning of the ScaleArc appliance.
Check for recent package updates by runningyum history.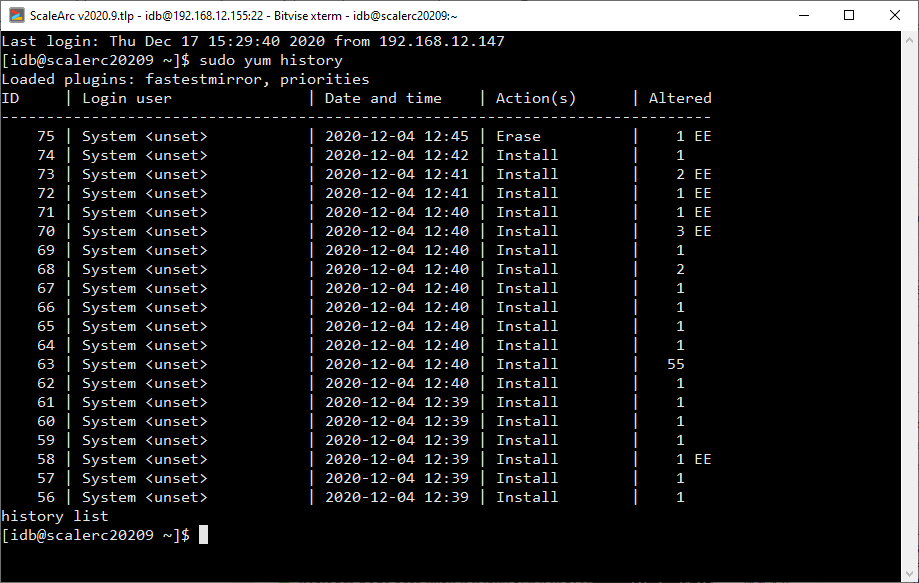
Packages that have been recently updated will have dates indicating when they were altered and can be inspected further using theyum history info <id> command. - Rollback any identified package updates by running
yum history undo <id> command. - The HA status should get back to normal on both nodes in the HA pair.
- Reboot both instances to clear up any configuration DB locks affecting the UI and ensure the nodes stay in a healthy state.
Testing
Perform manual failover tests to validate the HA configuration and test the HA configuration by adding or removing a database server from a cluster.
Comments
0 comments
Please sign in to leave a comment.