
Overview
One of the reasons that could cause the HA service to fail, resulting in the lack of active resource sync between the two HA nodes, configured virtual IPs (VIP) disappearing, and ultimately unsuccessful failover attempts is when the /dev/shm directory has restrictive permissions thereby blocking any write attempts to it by ScaleArc.
ScaleArc High Availability (HA) deployment provides uninterrupted operation that would otherwise occur when ScaleArc is running as standalone and became unavailable. One of the appliances in the HA pair functions as the primary node while the other as the secondary node ready to take over in case the primary is unable to accept connections.
Solution
Diagnosis
The primary ScaleArc node in a HA configuration will begin core dumping when it is unable to successfully failover to the secondary node anytime a failover attempt is triggered, either automatically or manually by an administrator.
Navigate to SETTINGS > HA Settings on the ScaleArc dashboard to confirm that the HA Service is down.
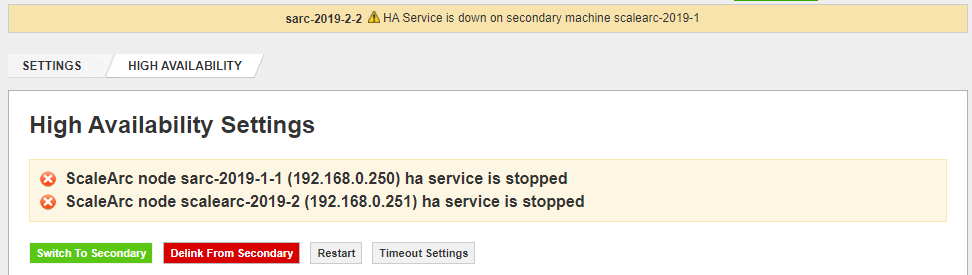
The following events will also be logged in the ScaleArc event logs on the UI as well as the /data/logs/services/alert_engine.log (Alert Engine log) file:
ScaleArc failed over to the standby instances with the following errors. <primary node hostname>
2020-10-12 09:05:42 ScaleArc recently encountered an issue that requires analysis. Please collect the relevant logs and send it to ScaleArc support.
2020-10-12 09:05:03 Peer node is standby. Potential disk issue. Please check <secondary node hostname>
2020-10-12 09:03:32 ScaleArc recently encountered an issue that requires analysis. Please collect the relevant logs and send it to ScaleArc support.
2020-10-09 13:30:29 Failover for Cluster bmirschp01my failed, Error verifying failover request: No valid standby server present
...
: alert_engine.publisher [publish]: (system_monitor) {'message': 'HA Service is down on secondary machine bmisarcmysqlp04', 'ident': 90, 'subject': 'System Monitor', 'cid': 0}
: (coredump) {: 'ScaleArc recently encountered an issue that requires analysis. Please collect the relevant logs (debuglogs.core.202010120903.tar.gz) and send it to ScaleArc support.
Further details on the root cause for the core dump alerts should be obtained by running the idblog_collector script and looking out for similar messages in the debug logs like the ones shown below from the /var/log/messages logfile:
Oct 12 09:01:13 cmysqlp03 cib[11187]: error: couldn't open file /dev/shm/qb-cib_ro-request-11187-6621-14-header: Permission denied (13)
Oct 12 09:01:13 cmysqlp03 cib[11187]: error: couldn't open file /var/run/qb-cib_ro-request-11187-6621-14-header: Permission denied (13)
Oct 12 09:01:13 cmysqlp03 cib[11187]: error: couldn't create file for mmap
Oct 12 09:01:13 cmysqlp03 cib[11187]: error: qb_rb_open:cib_ro-request-11187-6621-14: Permission denied (13)
Oct 12 09:01:13 cmysqlp03 cib[11187]: error: shm connection FAILED: Permission denied (13)
Oct 12 09:01:13 cmysqlp03 cib[11187]: error: Invalid IPC credentials (11187-6621-14).
Oct 12 09:01:13 cmysqlp03 python2.6: Found witness type: cluster
Oct 12 09:01:14 cmysqlp03 cib[11187]: error: couldn't open file /dev/shm/qb-cib_ro-request-11187-6808-14-header: Permission denied (13)
Oct 12 09:01:14 cmysqlp03 cib[11187]: error: couldn't open file /var/run/qb-cib_ro-request-11187-6808-14-header: Permission denied (13)
Oct 12 09:01:14 cmysqlp03 cib[11187]: error: couldn't create file for mmap
Oct 12 09:01:14 cmysqlp03 cib[11187]: error: qb_rb_open:cib_ro-request-11187-6808-14: Permission denied (13)
Oct 12 09:01:14 cmysqlp03 cib[11187]: error: shm connection FAILED: Permission denied (13)
Oct 12 09:01:14 cmysqlp03 cib[11187]: error: Invalid IPC credentials (11187-6808-14).
The list of configured Virtual IPs (VIPs) will be empty when you navigate to SETTINGS > Network Settings:
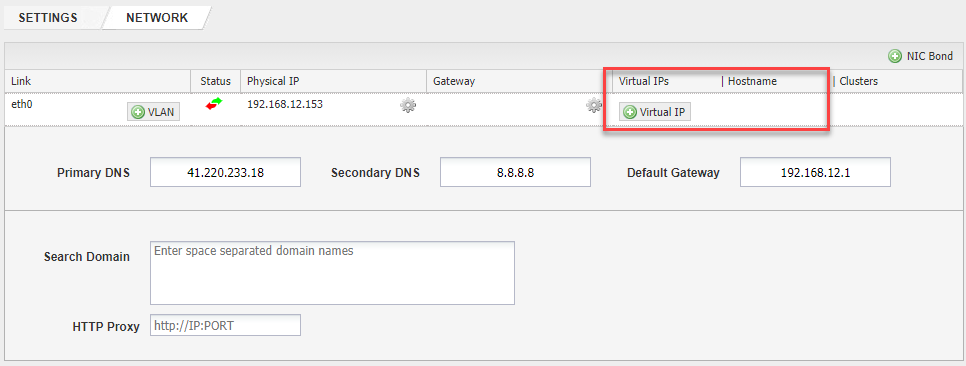
Steps To Fix
/dev/shm/* permission errors in the above debug logs and the missing VIPs are a strong indicator that a 3rd party application or an external process is altering the default permissions for this directory which is 777 to more restrictive permissions in an attempt to tighten the security of the Linux system. Typical 3rd party applications that are known to alter file system permissions include security solutions, data protection, and database audit tools such as Imperva Database Security Agent.
Changing the permissions of this directory to anything other than 777 causes the HA service to fail with the reported alerts and an HA failover attempt to occur.
Some of the files in /dev/shm are owned by hacluster:haclient user and group and the HA processes will not have access to them if the permissions are changed from 777 hence the HA failover errors.
Rebooting the appliance restores the /dev/shm permissions back to 777 which allows the HA services to run properly, or the permissions can also be changed from the terminal with chmod 777 /dev/shm. This may only be a temporary fix if the application that interferes with the directory permissions is not identified and stopped or configured to exclude /dev/shm from its actions.
/dev/shm directory.
Testing
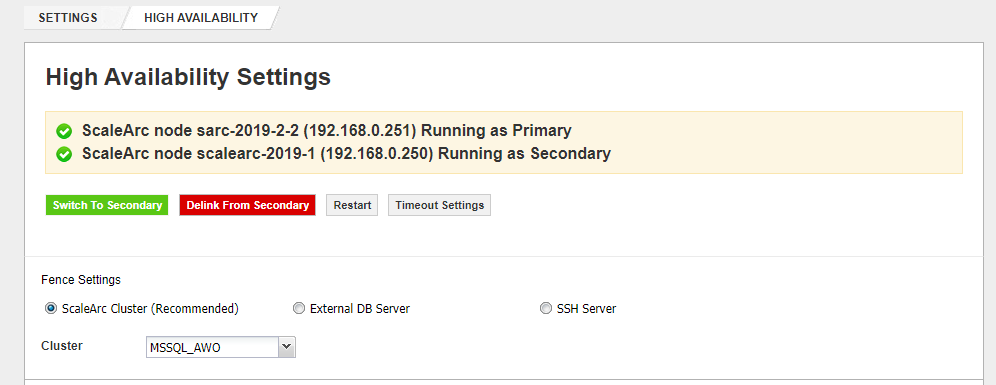
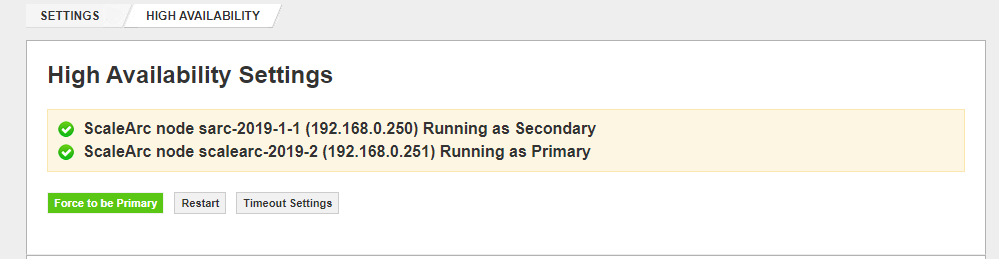
Once the directory permissions are corrected, navigate to SETTINGS > HA Settings on the ScaleArc dashboard on both the primary and secondary nodes to verify that the HA Service is running and any configured VIPs are now present under SETTINGS > Network Settings.
HA Settings on Primary node:
HA Settings on Secondary node:
Manual failover between both nodes should now succeed without the errors encountered before.
Comments
0 comments
Please sign in to leave a comment.