
Overview
A Split Brain situation is a state where each of the ScaleArc nodes in a HA setup believes it is the only active surviving node.
This article provides the steps to quickly recover from a HA Split-Brain situation if it occurs.
Prerequisites
- Access to the ScaleArc appliance via SSH
- Credentials for the
idbuser
Solution
Split-brain resolution is achieved using a witness server which is not a ScaleArc node.
The witness server is the system that keeps track of the current Primary node and in case of a split-brain, determine the node most capable of taking over resources and become the new primary.
Follow these steps to resolve the split-brain situation for older releases up to v3.11.0.2:
- Try to identify Secondary ScaleArc prior to the split-brain situation. If you are not sure, try the two methods below to identify which node was secondary:
-
# cat /etc/ha.d/haresources
- The host displayed here is usually the primary
-
# cat /logs/ha_idb.log
- This could reveal the primary/secondary instance prior to the split-brain situation
-
- Login to the Secondary ScaleArc UI and navigate to "SETTINGS > HA Settings" and click on the Restart button. This will restart the heartbeat on the Secondary ScaleArc and try to auto-resolve the split-brain.
- If the above step does NOT resolve the issue, then perform the following:
- SSH into the Secondary ScaleArc and stop the heartbeat service using the below command:
-
# sudo service heartbeat stop
-
- Login to the Primary ScaleArc UI and restart heartbeat
- The above 2 steps should resolve the split-brain situation
- Now start the heartbeat service on the Secondary ScaleArc using this command:
-
# sudo service heartbeat start
-
- SSH into the Secondary ScaleArc and stop the heartbeat service using the below command:
For newer versions released after v3.11.0.2 (i.e. 3.11.0.4, 3.12 or 20XX.X and later releases), follow these steps to resolve reported Fencing/Split Brain Resolution warnings:
- Confirm the HA service status on Primary and Secondary. This is done by navigating to SETTINGS > HA Settings on both the primary and secondary nodes to verify that the HA Service is running.
- Configure the fencing cluster to be one of the clusters, then change it to a different cluster and finally back to the original one.
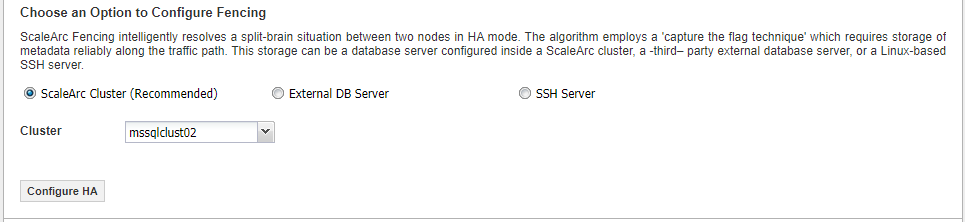
- The HA alerts should stop being logged confirming that HA is now operating as expected.
Comments
0 comments
Please sign in to leave a comment.